TL;DR
- Governance policy and governance monitoring are operationally different things
- SR 11-7’s ongoing monitoring pillar is consistently the most under-resourced
- Five parameters require continuous tracking in collections AI deployments
- Champion-challenger testing satisfies SR 11-7’s independent review requirement
- OCC examiners look for documented evidence, not stated intent
The OCC examiner’s question takes four words. “Show me your monitoring.”
Not “walk me through your governance framework.” Not “do you have a validation policy.” Four words, and the answer either exists in documented, operational form or it does not. In 2025 and 2026, that question has become the single most consequential moment in an AI model risk examination for US banks running collections AI.
Most banks have model governance policies. They have model inventories, approval workflows, validation checklists, and committee sign-off processes. What the examination question is really asking about is something different: AI governance monitoring, the continuous, real-time operational oversight of how AI collections models actually behave after they go live. And for a large number of US banks, that program either does not exist in a form that satisfies SR 11-7, or it has not been updated to account for what makes AI models fundamentally different from the statistical scorecards it was originally written for.
This article breaks down exactly what governance monitoring means for AI collections models, why collections AI creates monitoring challenges that most banks have not fully addressed, what SR 11-7 actually requires, and what a compliant program looks like in practice.
The Difference Between Model Governance and AI Governance Monitoring

It is worth being precise about language here because the conflation of these two terms is where most compliance gaps originate.
Model governance covers the structures, policies, and processes that oversee how AI models are developed, approved, deployed, and retired. It includes your model inventory, your model risk tiering framework, your validation independence requirements, and your committee approval chains. Most US banks have some form of this.
Governance monitoring is what happens after a model goes live. It is the ongoing operational verification that the model which passed validation on a given date is still performing as intended today, under current data conditions, in the current economic environment, and within every applicable compliance boundary. As the OCC’s Model Risk Management Comptroller’s Handbook puts it, banks must apply model risk management practices that include ongoing performance assessments to ensure models remain reliable over time.
SR 11-7, the Federal Reserve and OCC’s foundational AI governance framework and model risk guidance, has required this since 2011. The guidance explicitly defines ongoing monitoring as confirming that a model “is appropriately implemented and is being used and performing as intended,” and requires evaluation of “whether changes in products, exposures, activities, clients, or market conditions necessitate adjustment, redevelopment, or replacement of the model.” That is an operational program, not a policy document. And examiners evaluate whether governance “operates effectively in practice, not merely as written policy.”
The OCC’s Semiannual Risk Perspective for Fall 2025 reinforces this directly: “appropriate governance and risk management are essential to mitigate potential risks when implementing AI systems.” Appropriate governance, in examination context, means a functioning monitoring program with documented evidence of its operation.
Why Collections AI Creates Specific Monitoring Challenges
Not all AI models present the same monitoring demands. A static credit scorecard built on logistic regression changes slowly. You can validate it annually, run quarterly performance reviews, and have reasonable confidence that what the validation team approved in January is still substantially what you are running in December.
Collections AI operates on a different basis entirely. Four characteristics make it distinctly harder to monitor.
Self-learning models rewrite themselves between validation cycles.
An AI collections model that updates its behavior based on each production interaction is, technically, a different model each week. The version your model risk team validated in January may be meaningfully different from what runs in March. SR 11-7 requires that material changes to data, methodology, or assumptions trigger formal change management and re-validation before continued operational reliance. For self-learning architectures, this creates a genuine operational problem: you need monitoring that can distinguish routine parameter refinement from material behavioral change, and governance that responds accordingly.
Consumer payment behavior drifts constantly.
Concept drift occurs when the relationship between a model’s inputs and its target variable changes over time, even when the input data itself looks statistically stable. For collections AI, this is endemic. A model trained on payment behavior patterns from a low-interest-rate environment will behave differently when interest rates rise sharply. A model trained before a recession will misprice risk as unemployment climbs. The signals the model learned to rely on remain present in the data; they simply no longer predict what they once predicted.
Data feedback loops distort future training.
In collections, the model decides who to contact. The contact strategy changes how borrowers behave. That changed behavior becomes the next training dataset. The model is therefore, in part, learning from behavior it caused. This feedback loop is a well-documented source of model instability in interventional machine learning systems. Standard monitoring approaches that simply track aggregate performance metrics often miss this problem entirely until the drift becomes severe.
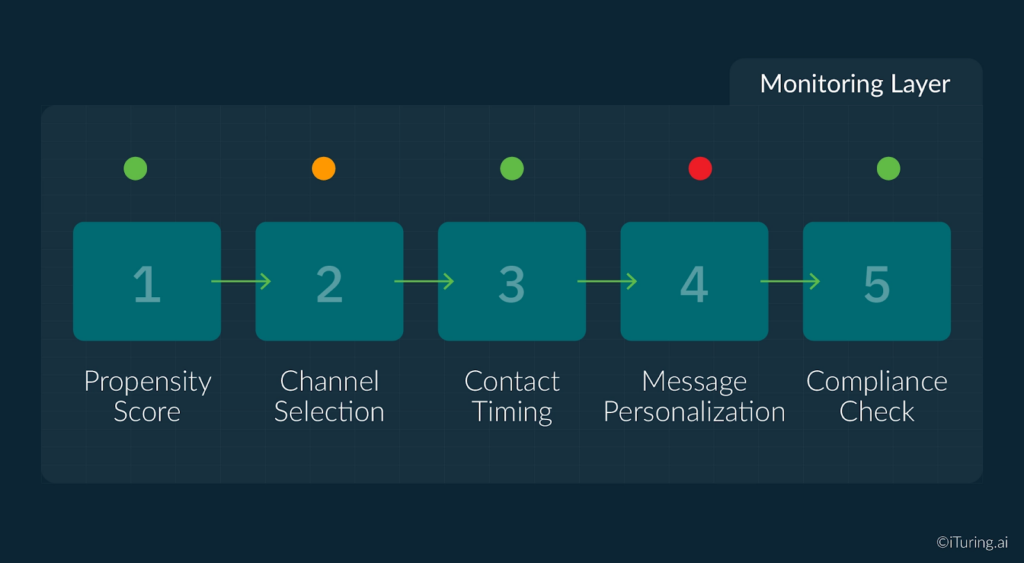
Multi-agent architectures multiply the monitoring surface.
Modern collections AI platforms are not single models. They are ecosystems of specialized agents: a propensity scoring model, a channel selection model, a timing optimization model, a message personalization model, and a compliance guardrail enforcement layer, all interacting within a single account contact decision cycle. Monitoring any individual agent in isolation is insufficient. Interactions between agents can produce emergent outputs that no single agent would generate on its own, and those emergent behaviors can create both performance and compliance risks. Enterprise AI governance programs must therefore treat multi-agent collections systems as a single interconnected monitoring surface, not a collection of independent models.
The Five Parameters That Must Be Monitored Continuously
A compliant governance monitoring program for collections AI tracks five distinct dimensions, each with its own early warning signal and escalation logic.

1. Data Drift
Data drift is a change in the statistical distribution of the inputs a model receives in production compared to what it was trained on. If the income distribution, debt-to-income ratios, account vintage profile, or delinquency bucket composition of your collections portfolio shifts materially, the model’s predictions may become unreliable even if the model architecture itself is unchanged. Monitoring for data drift means continuously comparing production input distributions against the training baseline, using statistical distance metrics, and triggering a structured review when divergence crosses a pre-specified threshold. The threshold itself must be documented and approved before deployment, so examiners can see that governance logic was set in advance rather than applied retrospectively.
2. Feature Drift
Feature drift focuses specifically on the predictive features a model relies on to make decisions. A feature that was highly predictive at training time, say the number of inbound customer-initiated contacts in the prior 14 days, may lose predictive power as contact behaviors shift with economic conditions or channel mix changes. Monitoring feature drift means tracking feature importance scores over time using explainability techniques and flagging when previously high-signal features decline in relevance below defined thresholds. For OCC examination purposes, feature drift monitoring also helps satisfy the explainability expectations the OCC’s Model Risk Management handbook now explicitly requires for AI models. Most AI governance frameworks that meet SR 11-7 standards now treat feature-level explainability as a distinct monitoring requirement, separate from model-level performance.
3. Model Performance Degradation
This is the most direct measure: is the model still predicting accurately? For a collections propensity model, standard performance metrics include the Gini coefficient, the Kolmogorov-Smirnov (KS) statistic, and the lift curve across deciles. When these metrics decline beyond a defined tolerance from their validation-time benchmarks, escalation is required. The critical governance requirement here is pre-specification: thresholds must be set before deployment, documented formally, and the escalation chain must be defined before any breach occurs.
4. Output Distribution Shift
Even when aggregate performance metrics appear stable, the distribution of model outputs can shift in ways that create operational and compliance risk. A propensity model that begins scoring 60 percent of accounts as high-contact-priority when it previously scored 35 percent has changed its effective operating behavior, even if its Gini coefficient has not moved. That shift has downstream consequences for contact volumes, staffing, channel spend, and potentially for fair lending compliance if the shift disproportionately affects protected classes. Output distribution monitoring catches these population-level shifts before they propagate into operational and regulatory problems.
5. Compliance Guardrail Adherence
This is the dimension unique to collections AI, and it is the one that connects model governance directly to consumer harm risk. FDCPA contact hour restrictions, TCPA prior express consent requirements, Regulation F’s seven-day contact frequency cap, and a growing body of state-level restrictions all impose hard operational limits on collections behavior. An AI model that respects all compliance guardrails on day one can drift toward violations if its optimization logic is updated without parallel compliance re-testing. Continuous automated monitoring of guardrail adherence rates, with immediate escalation on any breach, is the mechanism that keeps a model governance failure from becoming a consumer protection finding.
What AI Governance Frameworks Like SR 11-7 Require for Ongoing Monitoring
SR 11-7 is 22 pages. Its ongoing monitoring section is four paragraphs. Those four paragraphs are, in examination practice, among the most scrutinized requirements in the entire guidance document.
The Federal Reserve’s text specifies that ongoing monitoring must confirm that a model “is appropriately implemented and is being used and performing as intended,” and that it must “evaluate whether changes in products, exposures, activities, clients, or market conditions necessitate adjustment, redevelopment, or replacement of the model.” It requires benchmarking against alternative estimates. And it requires that all of this be documented in a form reviewable by independent parties.
The key obligation in SR 11-7 is also board-level involvement: institutions must ensure board-level oversight and periodic reporting of model risk exposures. For AI collections models, this means performance information must flow from operational monitoring through to the board’s risk committee on a defined reporting cadence, with trend data rather than point-in-time snapshots.
When OCC examiners review AI collections model monitoring programs in 2026, they focus on four operational questions:
- Monitoring frequency: How often is performance assessed, and is the frequency commensurate with the operational cadence of the model? For collections models that run daily decisioning, daily monitoring is the appropriate standard.
- Escalation procedures: When a threshold is breached, what happens? Who is notified, within what timeframe, and what is the interim risk mitigation while investigation proceeds?
- Retraining governance: What distinguishes a parameter update from a material model change requiring full re-validation? The OCC has increasingly flagged the absence of documented retraining governance as an AI-specific MRM finding.
- Board reporting cadence: Is senior management and the board’s risk committee receiving regular, documented model performance reporting, including trend analysis?
Verbal answers to those questions are not sufficient. The documentation must exist and must be reviewable on demand.
Champion-Challenger Testing as a Monitoring Mechanism
Champion-challenger testing is one of the most operationally effective tools available for satisfying SR 11-7’s simultaneous requirements for ongoing monitoring and independent review.
The framework works as follows: a challenger model, representing either a retrained version or an alternative architecture, runs in parallel with the production champion model. A defined proportion of accounts are routed through the challenger. Performance is compared continuously across pre-specified metrics. When the challenger demonstrably outperforms the champion, a governed transition process initiates, replacing the champion under full documentation and approval.
For SR 11-7 purposes, this achieves two things at once. First, it generates continuous empirical evidence that the production model remains optimal. This is exactly the kind of documented, comparative performance evidence examiners look for when assessing whether ongoing monitoring is functioning. Second, it creates a governed, auditable pathway for model updates that satisfies the OCC’s change management requirements for AI models.
KPMG’s Model Risk Management framework describes champion-challenger as a core element of sound validation practice: institutions should “develop champion model based on clearly defined model purpose and conduct quantitative and qualitative tests to ensure champion model is the best among various challenger models.” Running champion-challenger in production is not evidence of model instability. It is evidence that your governance monitoring program is operating as designed.
The Governance Monitoring Checklist
A compliant AI collections governance monitoring program, whether implemented directly or through an AI governance platform, contains seven operational components. Each requires documented ownership, defined thresholds, and a specified review cadence.

- Automated performance monitoring. Real-time tracking of Gini coefficient, KS statistic, and lift curves, with pre-specified alert thresholds and automated escalation triggers when thresholds are breached.
- Data drift detection. Continuous statistical comparison of production input distributions against training baselines, using population stability index or Jensen-Shannon divergence metrics, with automated flagging on threshold breach.
- Feature drift tracking. Ongoing monitoring of feature importance rankings using SHAP or equivalent explainability methods, flagging when previously high-signal features decline in relevance.
- Output distribution surveillance. Continuous monitoring of model output score distributions to catch population-level shifts that aggregate performance metrics may not surface.
- Compliance guardrail adherence reporting. Daily automated reporting on FDCPA, TCPA, and Regulation F compliance rates across all AI-driven contact decisions. Any guardrail breach triggers immediate escalation.
- Retraining governance protocol. Documented, board-approved criteria distinguishing routine parameter updates from material model changes requiring full re-validation. This must be approved before first production deployment, not defined reactively after a breach occurs.
- Board and senior management reporting schedule. A formal calendar for performance reporting to senior management and the board’s risk committee, including trend data across all five monitoring dimensions.
How iTuring Addresses This
iTuring’s enterprise AI governance platform for collections is built with governance monitoring as a foundational capability, not a post-hoc addition.
The platform monitors across 60 parameters in real time, covering data drift, feature drift, model performance, output distribution, and all applicable compliance guardrails simultaneously. Automated drift detection provides 2 to 4 weeks of early warning before model performance degrades to the point of requiring remediation. That lead time means institutions can respond with governed retraining rather than emergency intervention.
Champion-challenger testing is embedded in the deployment architecture. Every production model runs alongside a challenger by default, providing the continuous independent performance evidence SR 11-7 examinations require without requiring manual intervention to maintain. And one-click regulatory evidence generation produces examination-ready documentation covering monitoring activity, threshold breaches, escalation events, and remediation actions, organized in the format OCC and Federal Reserve examiners expect.
If you are building or reviewing your AI collections governance monitoring program, iTuring’s team can walk through what the operational framework looks like for your specific model architecture, regulatory relationship, and institutional risk appetite.
Regulatory Disclaimer
This article is for informational purposes only and does not constitute legal or compliance advice. Model risk management requirements vary based on institution type, asset size, regulatory charter, and supervisory relationship. The information presented here reflects general industry practice and publicly available regulatory guidance as of the publication date. Consult qualified legal and compliance professionals for guidance specific to your institution’s circumstances.
Sources: Federal Reserve SR 11-7 | OCC Semiannual Risk Perspective Fall 2025 | OCC Model Risk Management Comptroller’s Handbook | Equinox Compliance: SR 11-7 and AI | magicmirror.team: SR 11-7 MRM Guidance Explained | KPMG Model Risk Management | EvidentlyAI: Data Drift | EvidentlyAI: Concept Drift | Fiddler AI: Feature Drift Detection | IBM: Evolution of OCC MRM Expectations | Signzy: SR 11-7 Overview | teaminnovatics: AI Compliance Platform | Silent Eight: Model Drift in AI | AICorporation: Concept Drift in Interventional ML