TL;DR
- SR 11-7 applies to AI collections models, not just credit scorecards
- Self-learning and multi-agent architectures create validation challenges static models do not
- Conceptual soundness for ML models requires explainability, not just accuracy
- Documentation requirements are more extensive than most banks currently maintain
- Ongoing monitoring is the pillar most commonly found deficient in AI model examinations
Your bank almost certainly has a model risk management program. Your model risk management program was almost certainly built around credit scoring models.
Those two facts together describe the compliance gap that is showing up in AI model examinations across US banking in 2025 and 2026. The model risk those collections AI systems carry is not theoretical: it is the gap between what the governance framework was designed to catch and what a self-learning, multi-agent system can produce between validation cycles.
SR 11-7, the Federal Reserve and OCC’s foundational model risk guidance, does not distinguish between model types. A propensity model that scores 2 million collections accounts every morning is subject to the same validation framework as a credit underwriting scorecard. The same conceptual soundness requirements. The same ongoing monitoring obligations. The same documentation standards. And the same board-level oversight expectations.
The challenge is that the practices most US banks have developed to satisfy SR 11-7 were designed for static, interpretable, relatively slow-moving models. AI collections models are none of those things. They are self-learning. They involve multi-agent architectures where 20 or more components interact within a single decisioning cycle. They operate in consumer credit environments that shift constantly. And they produce outputs that are harder to explain, harder to validate, and harder to monitor than anything the original SR 11-7 guidance specifically anticipated.
This article covers what SR 11-7 actually requires, why collections AI makes those requirements harder to satisfy than credit scoring does, and what a complete, examination-ready MRM framework looks like for US banks running AI collections models.
What SR 11-7 Actually Requires
SR 11-7 has been the governing framework for model risk management in US banking since 2011. Most model risk professionals know it well. But it is worth being precise about the three core validation elements the Federal Reserve and OCC expect, because each one presents specific challenges for AI collections models that standard scorecard practice does not address.

The guidance defines a comprehensive validation framework around three core elements.
Evaluation of conceptual soundness. This involves assessing the quality of the model’s design and construction, including reviewing documentation and empirical evidence supporting the methods used and variables selected. For a logistic regression credit scorecard, conceptual soundness is relatively straightforward to establish: the methodology is well-understood, the variables are interpretable, and the relationship between inputs and outputs can be explained to an examiner in plain language. For a gradient boosting collections propensity model, the requirements are the same but the path to satisfying them is substantially more complex.
Ongoing monitoring. SR 11-7’s text is explicit: monitoring must confirm that the model “is appropriately implemented and is being used and performing as intended,” and must evaluate “whether changes in products, exposures, activities, clients, or market conditions necessitate adjustment, redevelopment, or replacement.” This is not an annual review obligation. It is a continuous operational requirement.
Outcomes analysis, including back-testing. Model outputs must be compared against actual outcomes and against estimates from alternative sources. Back-testing for a collections propensity model means comparing predicted payment probabilities against actual cure rates across account segments and time periods, with enough granularity to identify where and when the model begins to diverge from reality.
The OCC model risk management Comptroller’s Handbook adds further requirements specific to AI: appropriate due diligence and risk assessments as AI is implemented, sufficiently qualified staff to operate and control AI risks, an inventory of AI uses, and clear defined parameters governing the use of each AI system. OCC model risk management expectations have expanded considerably since the original 2011 guidance, particularly around AI explainability, inventory completeness, and defined use-case parameters for each deployed model. These requirements sit on top of SR 11-7’s baseline, and they are the areas where examinations of AI collections models most commonly surface findings.

Why Collections AI Is Different to Validate
Validating a static credit scorecard and validating a self-learning AI collections model are fundamentally different exercises. The regulatory framework is the same. The operational demands are not.
The model boundary problem. SR 11-7 is written for models with clearly defined boundaries: defined inputs, a defined methodology, and defined outputs. A modern AI collections platform does not work that way. It involves a cluster of interacting agents, each performing a specialised function: a propensity scoring model, a channel selection model, a timing optimisation model, a message personalisation model, and a compliance enforcement layer. These agents exchange information. The output of one becomes the input of another. Defining where one model ends and another begins, for the purposes of SR 11-7 model inventory and validation, is a genuinely difficult governance question that most banks have not yet resolved.
Deloitte’s 2026 guidance on managing AI agent risks in banking notes that banks should “expand their AI risk management frameworks to assess agents, not just models,” adding new risk categories like tool misuse, action validity, and outcome monitoring that standard MRM frameworks do not capture. That expansion is not optional for banks running multi-agent collections AI, it’s a prerequisite for a defensible governance position.
The self-learning update problem. A traditional scorecard is fixed between validation cycles. You validate it, deploy it, and the next validation happens on the same model. An AI collections model that updates its parameters based on production data is, in a meaningful sense, a different model each week. SR 11-7 requires that material changes to a model trigger a change management process and, where appropriate, re-validation before continued operational reliance. Determining what constitutes a material change in a continuously updating model requires explicit governance criteria that must be established before deployment, not developed reactively after an examiner asks.
The concept drift problem. Consumer payment behaviour changes with economic conditions. A model trained on payment patterns from one economic environment will encounter a different relationship between its input features and payment outcomes when conditions shift. PwC’s guidance on validating multi-agent AI systems notes that “validation must scale to include continuous monitoring and system-level oversight” because the interactions between agents, and between the model and its environment, create ongoing validation demands that a point-in-time examination cannot fully address.
The Model Validation Challenge: Conceptual Soundness for Collections AI
The conceptual soundness requirement is where AI collections model validation diverges most sharply from standard scorecard practice.
For a logistic regression scorecard, conceptual soundness means reviewing the statistical methodology, assessing variable selection, and confirming that the model’s coefficients are directionally consistent with economic intuition. An examiner can review the model documentation, understand the logic, and form a judgment about whether the methodology is sound.
For a gradient boosting or neural network collections model, this process is substantially harder. The OCC’s Comptroller’s Handbook states plainly that “AI techniques often result in a black box model, in which the underlying logic is a mystery,” and that “conceptual soundness assessment of AI models can be challenging.” The OCC’s response to this challenge is not to relax the conceptual soundness requirement. The requirement remains. The expectation is that banks will use explainability techniques to satisfy it.
Grant Thornton’s guidance on model conceptual soundness identifies the problem precisely: “Artificial intelligence techniques often result in a black box model, in which the underlying logic is a mystery. This presents an inherent challenge: if the methodology is not transparent, how can a reviewer independently assess its soundness?” The answer, in current OCC and Federal Reserve examination practice, is SHAP and LIME.
SHAP (SHapley Additive exPlanations) provides system-level model accountability by quantifying the contribution of each feature to every individual prediction, grounded in game theory. For a collections propensity model, SHAP analysis shows, at the individual account level, which features drove a high or low propensity score. This satisfies both the OCC’s conceptual soundness requirement and ECOA’s adverse action notice requirements.
LIME (Local Interpretable Model-Agnostic Explanations) generates case-level explanations by building a locally interpretable approximation of the model’s behaviour around a specific prediction. Where SHAP provides the system-level view, LIME provides the individual transaction-level explanation. Together, they give model risk teams the documentation needed to demonstrate that the model’s logic can be “reasonably understood by qualified individuals,” as SR 11-7 requires.
Back-testing requirements for AI collections models go beyond comparing predicted scores to outcomes. They require evaluating whether the model’s conceptual basis, meaning the relationships between input features and payment behaviour, remains valid as economic conditions change. Benchmarking against the bank’s existing rules-based collections system provides a practical alternative estimate for SR 11-7’s benchmarking requirement and gives examiners a reference point for evaluating whether the AI model delivers genuine improvement over the baseline.
Champion-Challenger as the SR 11-7 Bridge
The single most practical tool connecting SR 11-7’s validation requirements to the operational reality of a continuously evolving AI collections model is champion-challenger testing.
The framework is operationally straightforward. A challenger model, representing either a retrained version or an alternative methodology, runs in production alongside the champion. A defined proportion of accounts are routed through the challenger. Performance is compared continuously against pre-specified metrics. When the challenger demonstrably outperforms the champion, a governed transition replaces the champion under full documentation and approval.
For SR 11-7 compliance, champion-challenger serves three simultaneous functions. First, it satisfies the ongoing monitoring requirement by generating continuous, empirical performance data comparing the production model against an alternative estimate. SR 11-7 explicitly requires benchmarking against alternative estimates as a core element of ongoing monitoring, and champion-challenger is the most operationally rigorous way to satisfy this.
Second, it creates a governed change management pathway for model updates. When a challenger replaces the champion, the transition is documented, approved, and auditable. This directly addresses the OCC’s concern about undocumented changes to AI models, which TCS identifies as a primary risk factor in AI model governance.
Third, it provides the independent review evidence that SR 11-7’s validation independence requirements demand. Running a challenger that an independent team developed and monitors means the production model’s continued deployment is supported by ongoing empirical evidence from outside the model development team.
Documentation: What Examiners Will Ask For
Model documentation for AI collections models requires substantially more breadth than standard scorecard documentation. SR 11-7 compliance in examination context is ultimately evidenced not by stated policy but by the existence and retrievability of six specific documentation categories. The OCC’s validation requirements for AI specifically enumerate what must be maintained.
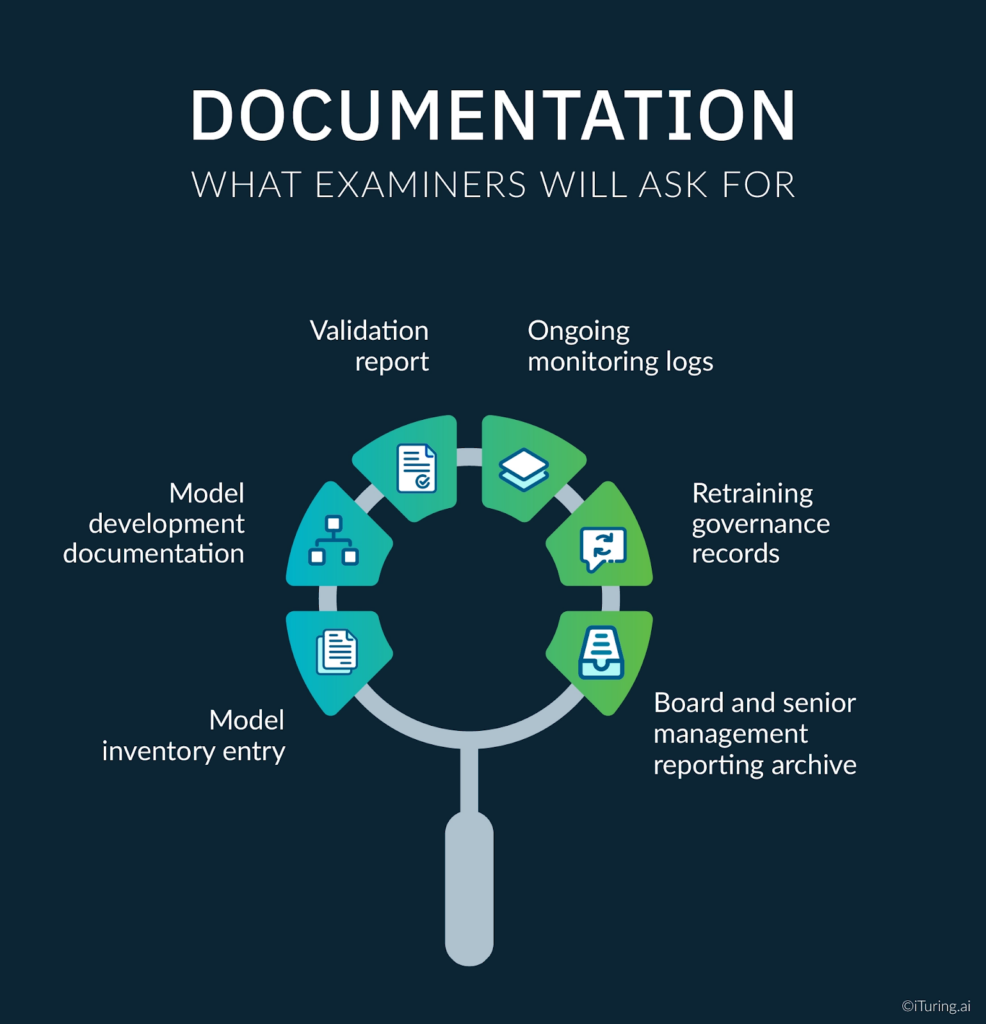
Model inventory entry. Every AI collections model, including every agent in a multi-agent workflow, must appear in the institution’s model inventory with owner, use case, validation status, tier classification, and deployment date. The OCC bulletin on model risk management clarification confirms that inventory completeness is a primary examination focus.
Model development documentation. Architecture documentation covering model purpose, methodology, training data provenance, feature engineering decisions, variable selection rationale, key assumptions, and known limitations. For AI models, this must include the explainability methodology used and the results of conceptual soundness testing.
Validation report. A formal validation report from an independent reviewer documenting the results of conceptual soundness assessment, out-of-time performance testing, SHAP analysis, disparate impact testing, back-testing against the rules-based baseline, and any weaknesses, limitations, or conditions attached to the approval.
Ongoing monitoring logs. Documented records of performance tracking from deployment date forward, including all threshold breach events, escalation actions taken, retraining decisions, and the governance approvals accompanying any material model changes.
Retraining governance records. The criteria used to distinguish parameter updates from material model changes, the approvals obtained for each retraining cycle, and the validation activities conducted before returning an updated model to production.
Board and senior management reporting archive. Records of performance reporting provided to senior management and the board’s risk committee, including the trend data and risk assessments included in each report.
The Orrick guidance on AI model diligence for financial institutions identifies board-level oversight documentation as a specific examination focus: “Institutions should draft comprehensive policies defining risk management activities regarding AI model implementation and oversight, including policies requiring Board and senior management oversight and approval.” That documentation must be current, consistent, and retrievable on demand.

Ongoing Monitoring: The Most Under-Resourced Pillar
Banks invest significant resources in model development and initial validation. Ongoing monitoring programs for AI models receive, on average, considerably less operational attention. This is the area where SR 11-7 examination findings for AI models are most frequently concentrated.
Grant Thornton’s analysis of ongoing monitoring in model risk management identifies the core requirement precisely: monitoring must verify that “internal and external data inputs continue to be accurate, complete, consistent with model purpose and design, and of the highest quality available,” with “active monitoring of data changes including data type, vendor, and repositories.” For AI collections models, this means monitoring is not simply a performance metrics dashboard. It encompasses data quality, feature stability, output distribution, and compliance guardrail adherence simultaneously. Critically, the model risk team must treat ongoing monitoring as a continuous extension of model validation, not a separate administrative exercise, because the model that passed validation on a given date is not necessarily the model running in production three months later.
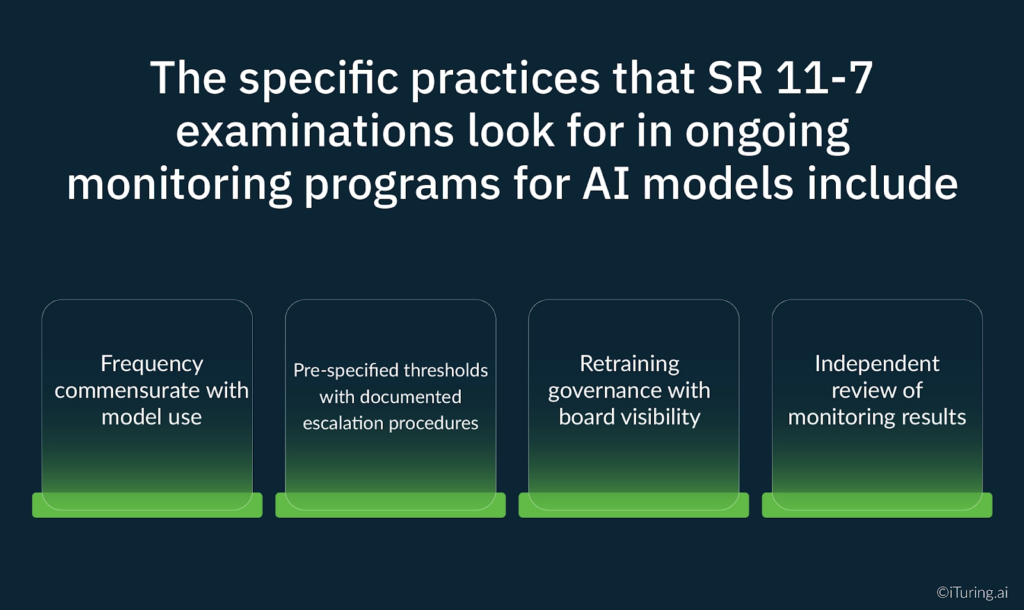
The specific practices that SR 11-7 examinations look for in ongoing monitoring programs for AI models include:
- Frequency commensurate with model use. A collections model that runs daily decisioning requires daily monitoring, not quarterly reviews.
- Pre-specified thresholds with documented escalation procedures. Monitoring thresholds must be set before deployment. Escalation procedures must be documented before any breach occurs. Post-hoc threshold definition does not satisfy the governance requirement.
- Retraining governance with board visibility. Every retraining cycle must follow a documented governance process, with material changes escalated to senior management and the board’s risk committee.
- Independent review of monitoring results. The same independence requirements that apply to initial validation apply to ongoing monitoring. The team producing monitoring reports cannot be the same team responsible for model performance.
The ValidMind analysis of SR 11-7 compliance in 2025 observes that “modern practices go beyond traditional accuracy metrics, creating tests for bias, fairness, and model drift.” For AI collections models specifically, the monitoring program that satisfies examination standards in 2026 looks substantially different from the monitoring program that would have been considered adequate for a scorecard validation in 2015.
How iTuring Addresses This
iTuring’s collections AI platform is built with SR 11-7 compliance as an architectural requirement, not an implementation afterthought.
The platform’s model governance module maintains a complete, audit-ready model inventory covering every model component in the collections AI architecture, with automated tracking of validation status, deployment dates, retraining events, and performance history. SHAP and LIME explainability are generated at both the portfolio level and the individual account level for every prediction cycle, providing the conceptual soundness documentation SR 11-7 examinations require.
Champion-challenger testing is embedded in the deployment architecture by default. Every production model runs against a challenger continuously, producing the independent performance comparison that both satisfies SR 11-7’s benchmarking requirement and creates the governed change management pathway the OCC requires for AI model updates.
One-click audit documentation generates examination-ready packages covering all SR 11-7 documentation requirements, including monitoring logs, escalation records, retraining governance decisions, and board reporting history, formatted for OCC and Federal Reserve examination review.
If your institution is building or reviewing its MRM framework for AI collections models, iTuring’s team can walk through how the platform’s governance architecture maps to your specific regulatory relationship and model risk tier classifications.
Regulatory Disclaimer
This article is for informational purposes only and does not constitute legal or compliance advice. SR 11-7 model risk management requirements and OCC examination standards vary based on institution type, asset size, regulatory charter, and supervisory relationship. The information presented reflects general industry practice and publicly available regulatory guidance as of the publication date. Consult qualified legal and compliance professionals for guidance specific to your institution’s circumstances.
Sources: Federal Reserve SR 11-7 | Federal Reserve SR 11-7 Attachment | OCC Model Risk Management Comptroller’s Handbook | OCC MRM Clarification Bulletin 2025 | IBM: Evolution of OCC MRM Expectations | Grant Thornton: Conceptual Soundness | Grant Thornton: Ongoing Monitoring in MRM | BIS: Managing AI Explainability | NASSCOM: SHAP and LIME in BFSI | KPMG: Model Risk Management | Baker Tilly: OCC MRM Guidance | Deloitte: Managing AI Agent Risks in Banking | PwC: Validating Multi-Agent AI Systems | TCS: AI Transforming Model Risk Management | Orrick: AI Model Diligence for Financial Institutions | ValidMind: SR 11-7 Compliance | Management Solutions: OCC Safety and Soundness | Apparity: OCC 2021 MRM Guidance | PopProbe: MRM Validation Checklist