





Key Takeaways
- SR 11-7 model risk management guidance now applies to AI collections models with the same rigor as credit risk systems
- Nine audit artifacts required covering inventory, lineage, development, explainability, fairness, monitoring, audit trails, validation, and retraining
- Retrofitting governance after deployment creates broken lineage and week-long root cause analysis versus 30-minute integrated approaches
- Automated documentation platforms generate complete audit packages in 40 minutes versus weeks of manual compilation
- Continuous monitoring of 60+ parameters replaces annual validation as leading practice for regulatory readiness
Regulators now apply SR 11-7 model risk management guidance to AI collections systems with the same rigor they use for credit risk models. Banks using AI for debt collection face a new reality. Saying “the model works” no longer satisfies compliance requirements. Examiners want nine specific artifacts documenting every aspect of how you built, deployed, and monitor your models.
Banks that cannot produce complete audit artifacts face enforcement actions, operational restrictions, and reputational damage. The timeline is typically tight—documentation requests require rapid response.
This guide covers the nine artifacts examiners will request, why retrofitting governance after deployment fails audits, and how to achieve continuous compliance readiness.
The new normal for collections AI
SR 11-7 model risk management establishes a framework with three pillars: development, validation, and governance. Regulators originally wrote this guidance for credit risk models. Now they apply the same framework to any AI system making material business decisions, including collections optimization, payment propensity prediction, and delinquency forecasting.
Documentation replaces trust
SR 11-7 requires documentation detailed enough that someone unfamiliar with your model can understand how it operates, what its limitations are, and what assumptions it makes. An examiner needs to reconstruct your model logic without asking your data science team to explain it.
A housing finance company managing a $21 billion portfolio deployed behavioral collections models that achieved 83% accuracy and improved collection rates by 39-44%. When preparing for regulatory review, the iTuring platform generated complete artifacts showing feature derivation, algorithm rationale, validation results, and fairness testing. Banks without this capability face choices between halting model use or operating under heightened scrutiny.
Three regulatory expectations that matter
Three compliance expectations define the current regulatory environment for collections AI.

First, third-party model validation is mandatory. Banks using vendor-provided collections models must validate them as rigorously as models they build internally. You cannot simply trust vendor assertions. The burden of proof sits with your institution.
Second, continuous monitoring demonstrates stronger risk management than annual validation. While annual reviews satisfy minimum requirements, continuous monitoring of key performance and risk parameters shows proactive governance rather than reactive compliance.
Third, bias and fairness analysis moved from optional to mandatory. Collections models showing differential treatment by protected classes create immediate regulatory risk regardless of statistical justification. Fairness testing must occur before production deployment, not during audits.
Nine artifacts you need ready
Banks must produce all nine artifacts when examiners request them. Missing even one creates compliance gaps that regulators will flag.
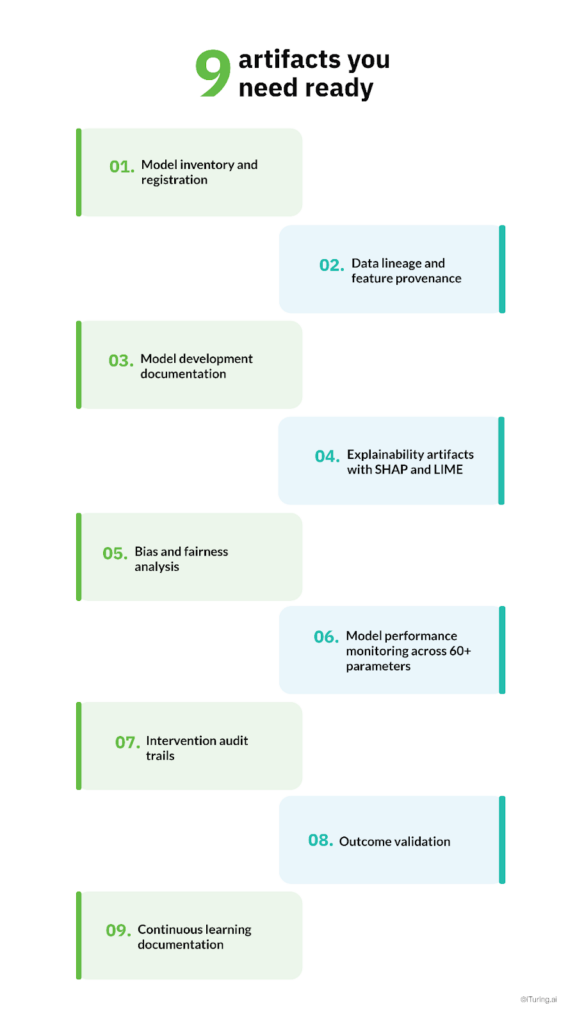
1. Model inventory and registration
Start with a comprehensive list of every model in development, validation, and production. For each collections model, document who owns it, who uses it, who built it, what version runs in production, and when someone approved it for deployment.
The iTuring platform maintains unlimited model registry with electronic approval workflows that enforce maker-checker controls. Git-style version control lets you roll back to previous versions if performance degrades. Shadow models, informal algorithms people use for business decisions but never formally registered, create immediate compliance violations.
2. Data lineage and feature provenance
You need documentation tracing every feature from its raw source through all transformations to the final model input. Take a feature like “30-day transaction velocity” as an example. Examiners want proof showing how this feature derives from raw transaction records, what transformations you applied, and what assumptions the calculation makes.
The iTuring Feature Store provides immutable audit trails with DAG visualization showing your complete workflow. The system traces how 8 raw transaction variables become 8,000 transaction pattern features, 80 bureau variables transform into 7,000 behavioral signals, and 5 delinquency data points generate 1,500 payment pattern features. This automated lineage eliminates manual reconstruction when examiners request feature provenance documentation.
3. Model development documentation
This explains why you selected specific algorithms, features, and hyperparameters. The documentation needs enough detail that an independent third party could replicate your work.
iTuring generates comprehensive documentation automatically covering data treatment, feature selection, algorithm rationale, and validation approaches. When a payment bank needed regulatory approval for merchant churn models, iTuring delivered complete documentation in 40 minutes. The automation eliminates weeks of manual compilation reconstructing development decisions data scientists made months earlier.
4. Explainability artifacts with SHAP and LIME
Collections models that trigger adverse actions like lawsuits or asset seizures require detailed explanations. Examiners look for two types of explainability. Global explainability shows what features generally drive your predictions. Local explainability shows why a specific customer received a specific score.
The iTuring platform provides SHAP values, LIME explanations, feature importance rankings, partial dependence plots, and individual prediction explanations. The system also includes Neuro Signal Tracing, which provides exact explanations rather than surrogate model approximations. This distinction matters for complex neural networks where LIME approximations may not satisfy regulatory precision requirements.
5. Bias and fairness analysis
Fairness testing is no longer optional. You need documentation proving your models do not exhibit disparate impact on protected classes including race, gender, age, and national origin.
Banks must demonstrate three things: you measured model outcomes by protected class subgroups, you ran statistical tests for significant differences in treatment, and you documented remediation if bias exists. Saying “we considered fairness” means nothing without quantitative evidence.
iTuring fairness scorecards measure discrimination across sensitive features and automatically flag differential treatment during model development. This prevents biased models from reaching production instead of discovering problems during audits.
6. Model performance monitoring across 60+ parameters
Effective model drift detection separates compliant operations from enforcement targets. Regulators expect documentation showing what parameters you monitor, how often you check them, what thresholds trigger intervention, and what actions you take when thresholds breach.
The iTuring MRM platform monitors 60+ parameters continuously with alerts generated within one minute of detecting anomalies. Parameters include model performance metrics like AUC, F1, Precision and Recall when you have feedback, plus CI Model Relevancy Score, PSI and CSI when you lack ground truth labels. The system also tracks distribution metrics, data quality measures, and feature quality scores.
Early warning indicators predict model failure 2-4 weeks before business impact occurs. The housing finance company used continuous monitoring to detect collections model drift and documented the complete investigation rapidly.
7. Intervention audit trails
Every model decision, override, adjustment, and outcome needs audit trail documentation. Examiners look for evidence that decision-making follows established policies, that someone appropriately justified and approved overrides, and that override patterns do not indicate systematic model failure.
The iTuring platform creates immutable audit trails with timestamps for every action. Model failures, drift detections, and all changes to data, features, or algorithms get automatically documented in comprehensive reports. Every AI action includes detailed, exhaustive, and transparent documentation.
8. Outcome validation
Outcome validation compares your model predictions against actual results. For collections models this means tracking whether customers predicted to have high payment propensity actually paid, whether predicted delinquency progressions materialized, and whether contact strategies produced expected response rates.
SR 11-7 requires champion-challenger model testing to ensure deployed models outperform alternatives. You must document your testing methodology, prove statistical significance of performance differences, and explain why you selected the champion.
The housing finance company tracked outcome validation for behavioral collections models across three delinquency buckets, demonstrating that 83% prediction accuracy identifying highest-risk accounts 120 days before delinquency translated to measurable improvements in collection rates.
9. Continuous learning documentation
Collections models in production require periodic retraining as customer behaviors evolve and economic conditions change. Regulators want documentation of retraining frequency, what triggers retraining, how performance compares between old and new versions, and what approval process you follow before deploying retrained models.
The iTuring platform supports three learning modes: incremental learning updates models with new data, partial learning retrains specific components, and complete learning rebuilds the entire model. The system documents automated retraining approval workflows showing when retraining was triggered, what performance changes resulted, and what approval was obtained before deployment.
Why retrofitting governance always fails
Banks that assemble SR 11-7 model risk management from separate tools face insurmountable audit challenges. Building models in one system, deploying through another, and monitoring in a third creates three failure modes.
Broken lineage across systems
Retrofitting governance fails SR 11-7 compliance because data scientists build collections models in Python, data engineers deploy them through custom Java APIs, and business analysts track performance in Tableau dashboards. When examiners request data lineage, you must manually reconstruct feature transformations across three systems with no automated traceability.
Integrated platforms solve this through end-to-end traceability. The iTuring platform maintains lineage from raw data through feature engineering through model development through production deployment through monitoring. DAG visualization shows the complete workflow with immutable audit trails at each step, requiring no manual reconstruction.
Root cause analysis takes weeks instead of minutes
When model performance degrades, regulators expect rapid root cause analysis with documented remediation. Separate tool architectures require manually checking data quality issues, feature distribution shifts, and algorithm performance degradation across different systems.
The iTuring platform compresses root cause analysis from weeks to 30 minutes. The system automatically correlates data drift, feature drift, and model drift to pinpoint exactly where degradation originates. When the housing finance company detected collections model drift, iTuring identified the root cause and generated complete documentation rapidly.
Compliance as afterthought versus compliance as code
Integrated platforms embed compliance requirements into the development process rather than adding them afterward. The iTuring platform implements compliance as code where you configure regulatory requirements upfront and they govern all subsequent model development, deployment, and monitoring.
When a bank starts a collections model project, they configure SR 11-7 requirements, documentation standards, fairness testing protocols, and monitoring parameters before building the model. The platform then enforces these requirements automatically, preventing non-compliant models from reaching production.
Separate tool approaches treat compliance as a documentation exercise after model deployment. Data scientists build models optimizing for business metrics. Compliance teams manually create documentation for audit purposes months later. This creates gaps, inconsistencies, and information requests that data scientists no longer remember.
Building audit-ready infrastructure
Achieving audit readiness requires three technical capabilities.
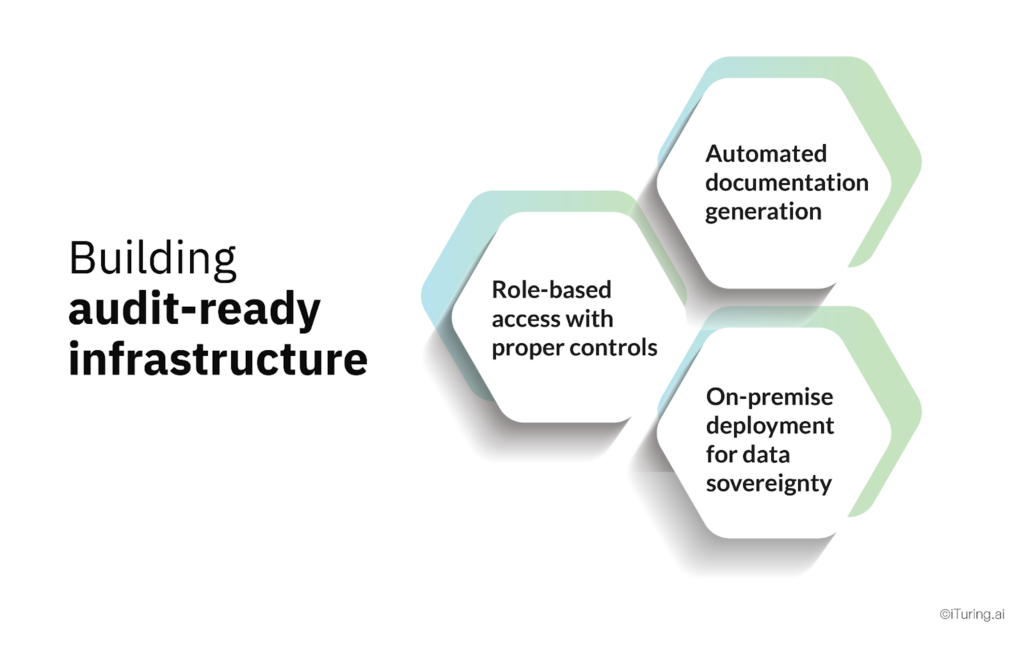
Automated documentation generation
Manual documentation fails because data scientists test hundreds of feature combinations, algorithm variations, and hyperparameter configurations during development. Reconstructing the path from raw data to production model requires documentation discipline that few organizations maintain.
The iTuring platform generates comprehensive documentation automatically at every stage. Development documentation includes data treatment approaches, feature engineering methodology, algorithm selection rationale, hyperparameter tuning results, and validation strategies. Validation documentation includes performance metrics on development and holdout samples, explainability artifacts with SHAP and LIME values, fairness scorecards, and bias analysis.
When a payment bank needed regulatory approval for their merchant churn model, iTuring delivered complete documentation in 40 minutes. The documentation included feature importance rankings showing that transaction velocity and engagement patterns drove predictions, validation results proving 92% accuracy across samples, and fairness testing confirming no protected class bias.
Role-based access with proper controls
Governance requires proper segregation of duties. Model developers should not have production deployment authority. Business users should not modify model algorithms. Compliance officers need read-only access to all documentation.
The iTuring platform implements role-based access control with granular permissions. Model developers can build and test models but need approval for production deployment. Model validators can review and approve but cannot modify model logic. Business users can access predictions and explanations but not underlying algorithms.
Electronic approval workflows enforce maker-checker controls. A data scientist develops a collections model and submits for validation. A model validator reviews documentation, tests performance, and either approves or rejects. If approved, a production deployment manager releases to production with final authorization. Every step gets logged in immutable audit trails.
On-premise deployment for data sovereignty
Many banks face regulatory requirements restricting where sensitive customer data can reside. Cloud-only AI platforms create compliance challenges when regulators require on-premise processing of personally identifiable information.
The iTuring platform supports on-premise or cloud deployment with identical functionality. Banks can deploy the complete platform within their data center perimeter while maintaining full control over data movement and storage. This enables use of behavioral data for collections models without transferring customer information to external systems.
Your audit preparation approach
Banks preparing for regulatory examinations face documentation preparation challenges. This approach moves from unprepared to audit-ready systematically.
Inventory and ownership verification
Export your complete model inventory from production systems. For each collections model, document the model ID, version, deployment date, last validation date, who owns it, who uses it, and how you classified its risk.
Verify that all models running in production appear in your inventory. Shadow models create immediate compliance violations—these are informal algorithms people use for business decisions but never formally registered. Find them and either decommission them or register them properly.
Confirm model ownership assignments because every model requires a designated owner responsible for ongoing performance monitoring. Review approval workflows and verify that all production models received appropriate authorization before deployment.
Documentation assembly and gap analysis
Compile model development documentation for all collections models. If you use iTuring, run one-click documentation generation. If you use manual processes, collect development notes, code repositories, and validation reports. Ensure documentation explains algorithm selection, feature engineering, and validation approaches.
Generate explainability artifacts by running SHAP analysis for key models, creating feature importance visualizations, and documenting prediction drivers. Prepare local explanations for representative customer examples showing why you assigned specific scores.
Conduct fairness testing if you have not done this previously. Run statistical tests for disparate impact across protected classes and document any findings plus remediation actions. Missing fairness analysis raises regulatory concerns.
Organize documentation in an examiner-friendly format with a clear index showing where each required artifact lives. Unclear or difficult-to-navigate documentation suggests weak governance even when your content is adequate.
Performance validation and monitoring review
Pull production performance metrics for all collections models and compare current performance against original validation benchmarks. Document any degradation and explain what caused it.
Review model monitoring logs and alert history to demonstrate that monitoring is active, you investigate alerts, and you take appropriate actions when thresholds breach. Missing monitoring or ignored alerts indicate weak risk management.
Conduct outcome validation analysis by comparing model predictions against actual customer behavior. Calculate accuracy, lift, and business value metrics and document your findings in formal reports.
Prepare retraining documentation showing when you last retrained models, what triggered retraining, how performance changed, and what approval you obtained. If models have not been retrained in over 12 months, document your justification.
Three gaps examiners flag repeatedly
Three documentation gaps appear frequently in examinations of AI collections systems.
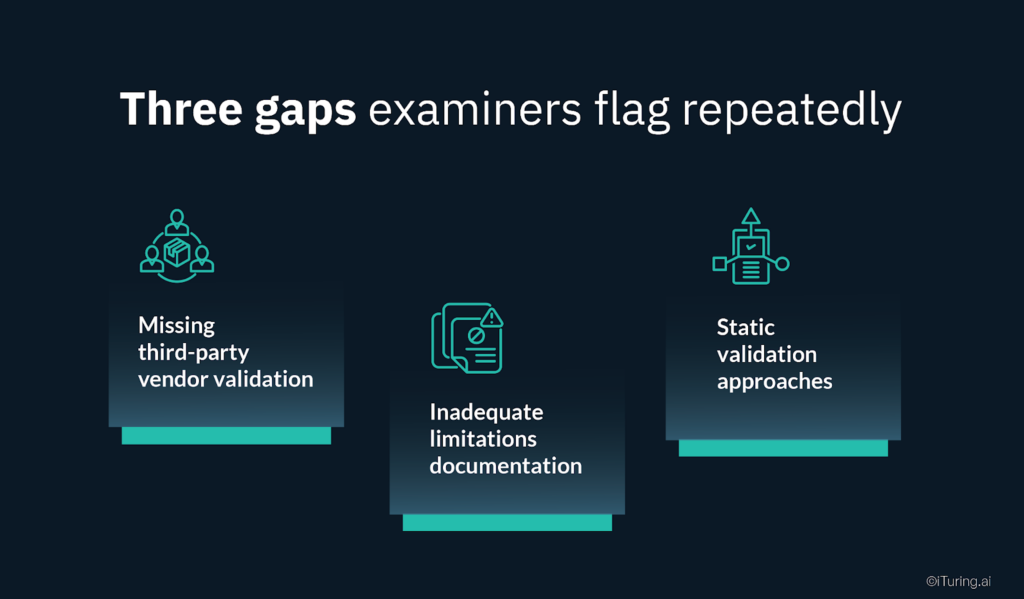
Missing third-party vendor validation shows up constantly. Banks use credit bureau data, external collections platforms, or vendor-provided models without documenting independent validation. SR 11-7 explicitly requires analysis of integrity and applicability of information provided by third-party vendors. Simply trusting vendor assertions violates the guidance.
Inadequate limitations documentation creates problems because every model has limitations around data quality, algorithmic assumptions, or use case boundaries. Examiners expect explicit documentation of what your model cannot do, not just what it can. Missing limitations documentation suggests developers do not understand model risks.
Static validation approaches satisfy minimum requirements but suggest weak risk management. Annual model validation meets the baseline, but leading practices include continuous monitoring, quarterly performance reviews, and event-driven revalidation when business conditions change materially. Banks relying solely on annual validation often face examiner questions about their responsiveness to emerging risks.
Moving from audits to continuous compliance
Sustainable compliance requires shifting from point-in-time preparation to continuous readiness.

Continuous monitoring replaces periodic reviews. The iTuring MRM platform tracks 60+ parameters in real-time with alerts generated within one minute of detecting problems. Banks know immediately when models drift rather than discovering issues during scheduled validation.
Automated documentation replaces manual compilation. Instead of spending weeks assembling materials, one-click generation produces complete packages in minutes. Documentation stays current automatically as models retrain and evolve.
Embedded governance replaces retrofitted compliance. Configuring requirements upfront ensures models meet standards before deployment rather than discovering gaps during examinations. Compliance as code prevents non-compliant models from reaching production in the first place.
Banks implementing continuous compliance approach examinations with confidence. When examiners request documentation, you have it immediately available. When they ask about recent performance, current monitoring data answers the question. When they probe limitations and risk management, your governance framework demonstrates ongoing oversight rather than audit-driven activity.
Resolution
Regulatory examinations of AI collections systems focus on the nine artifacts representing minimum standards for defensible model governance: inventory, lineage, development documentation, explainability, fairness analysis, performance monitoring, audit trails, outcome validation, and continuous learning protocols.
Manual approaches consume hundreds of data scientist hours per examination with week-long cycle times for root cause analysis. Automated platforms compress investigations to 30 minutes with continuously maintained documentation.
The housing finance company managing a $21 billion portfolio demonstrated the integrated approach: 83% prediction accuracy through behavioral models, 39-44% collections improvement, complete regulatory documentation generated automatically, and continuous monitoring of model performance. A payment bank achieved 92% churn prediction accuracy with complete audit documentation produced in 40 minutes.
For banks under $5 billion, achieve baseline compliance and plan platform investment to move from reactive to proactive governance. For banks between $5 billion and $50 billion, deploy integrated MRM platforms monitoring all collections models with 30-minute root cause analysis replacing multi-week investigations. For banks above $50 billion, build enterprise model risk management infrastructure covering all AI systems and leverage compliance as code to prevent governance gaps rather than discovering them during examinations.
The regulatory expectation is clear. AI collections systems face the same documentation and governance standards as credit risk models. The nine artifacts are mandatory, not aspirational. Integrated platforms with automated documentation, continuous monitoring, and embedded compliance separate well-governed institutions from those operating on borrowed time.














