





TL;DR
- Only 43.63% of Indians speak Hindi as mother tongue; English reaches far fewer
- India loses over Rs. 500 crore yearly from language-related collections miscommunication
- Regional language SMS and WhatsApp messages get 35-40% higher response rates
- NBFC credit in Tier 2/3 cities is growing at 21% YoY, making vernacular a business priority
- iTuring supports 10 regional languages with compliance-validated tone across all channels
“Payment nahi kar sakta” (I cannot make the payment).
“Payment karne mein dikkat hai” (I am having difficulty making the payment).
One signals inability. The other signals a temporary constraint. For a collections agent or an AI system deciding what to do next (escalate, offer a payment plan, or hold) the distinction determines the entire resolution strategy. And it only becomes visible if the system is listening in the borrower’s language, with enough cultural depth to catch the difference. As researchers tracking India’s collections landscape have noted, India loses over Rs. 500 crore every year in debt recovery not from bad debts, but from cultural miscommunication during collections.
This is the vernacular problem in Indian debt collection. It is not about translation. It is about comprehension, trust, and the signal-to-noise ratio in a conversation that directly determines whether money moves. A banking ai platform deployed in India without vernacular capability is not a collections tool for the majority of the country’s borrower base. It is a tool for the fraction of that base that happens to be comfortable in Hindi or English.
The Vernacular Imperative: What the Language Data Actually Says
The assumption that India is an English-speaking country has driven more than a few collections strategies into the ground.
According to India’s 2011 Census data, Hindi is the most widely spoken language in India at 43.63% of the population as mother tongue. English, despite its status as an official language, is the mother tongue of fewer than three lakh Indians. As a second language, English reaches approximately 10-15% of the population, mostly urban, mostly educated, mostly already well-served by formal financial institutions.
The remaining picture looks like this. According to mother tongue data from the 2011 Census:
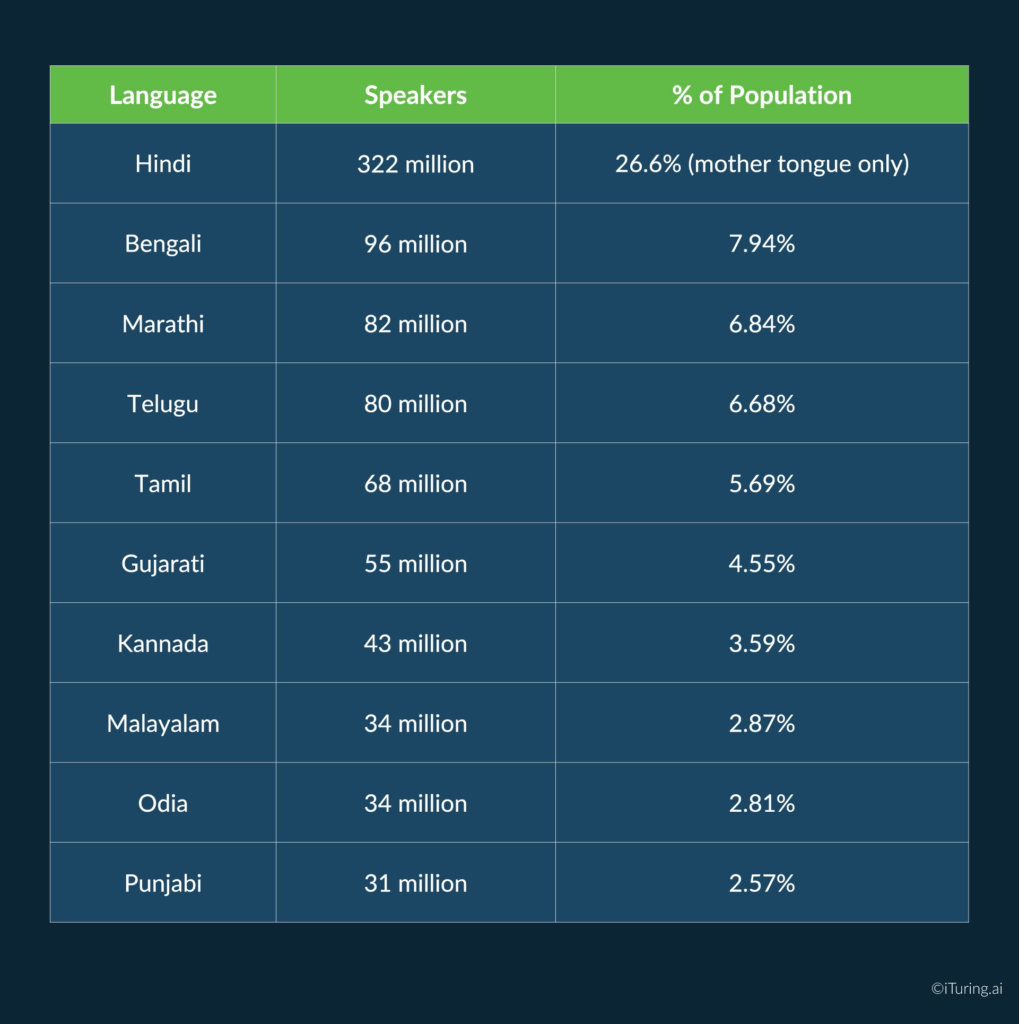
These are not niche populations. Bengali has more speakers than the entire population of the United Kingdom. Telugu speakers outnumber the population of Germany. A collections operation that communicates only in Hindi and English is functionally invisible to a significant share of the borrowers it is trying to reach.
The geographic concentration makes this even more operationally concrete. Tamil Nadu’s primary borrower population speaks Tamil. Andhra Pradesh and Telangana speak Telugu. West Bengal speaks Bengali. Maharashtra’s Tier 2 and 3 cities (Nashik, Aurangabad, Nagpur, Kolhapur) speak Marathi. Gujarat’s rapidly expanding MSME lending market speaks Gujarati. In each of these geographies, a collections call or message in Hindi or English is perceived as foreign-language communication, and foreign-language communication gets ignored at far higher rates.
Why Language Determines Recovery: Three Mechanisms
The 30% recovery rate improvement that vernacular collections delivers is the compound result of three distinct mechanisms operating simultaneously.
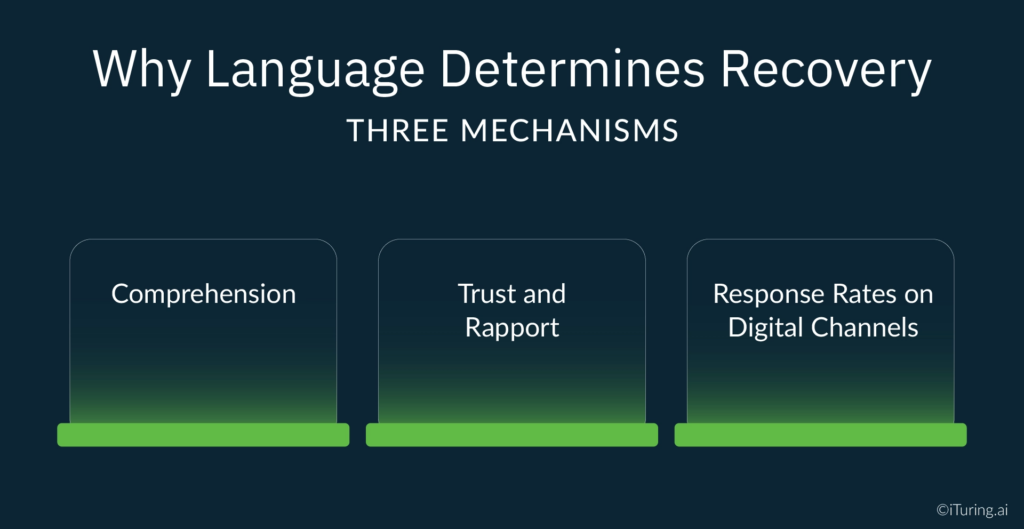
Comprehension
A borrower who does not fully understand a payment notice does not respond to it, not because they are unwilling, but because they are uncertain. What is the exact amount? What is the deadline? What happens if they pay part of it? If the answer to any of these questions requires them to re-read a message in a language they are not fully comfortable with, the path of least resistance is to set it aside and deal with it later. Later often becomes never.
Regional language communication eliminates this friction entirely. The borrower reads the notice in their mother tongue, understands the terms immediately, and can act on it without cognitive effort. That reduction in friction directly translates into a faster payment decision.
Trust and Rapport
Language carries a social signal beyond its informational content. When a lender communicates with a borrower in their mother tongue, it signals that the institution sees them as a whole person, not just a loan account number. In communities where financial institutions have historically been perceived as distant and urban-centric, this signal carries real weight.
Industry practitioners tracking collections behaviour in Tier 2 and 3 markets consistently note that vernacular communication reduces the defensive posture that many borrowers adopt when they receive a collections contact. That defensive posture is also a churn prediction signal: a borrower who stops responding across all channels simultaneously (calls, SMS, WhatsApp) is exhibiting disengagement behavior that a churn prediction model distinguishes from simple payment stress. In regional language markets, a significant proportion of that disengagement traces back to language-driven friction rather than genuine non-cooperation, and vernacular communication resolves it before the churn prediction model ever needs to intervene.
Response Rates on Digital Channels
The response rate differential is measurable and significant. SMS, WhatsApp, and IVR messages sent in a borrower’s regional language achieve 35-40% higher response rates compared to the same message in Hindi or English for non-Hindi-belt and non-urban borrowers. On WhatsApp specifically, which has over 530 million users in India and penetrates deeply into Tier 2 and 3 cities, the response rate advantage of vernacular messaging is compounded by the platform’s conversational nature. A borrower who receives a WhatsApp message in Tamil and can respond in Tamil is experiencing a genuinely different interaction than one navigating an English-language payment flow.

AI Collections in Regional Languages: The Technical Reality
Implementing vernacular collections at scale requires confronting a set of genuinely difficult technical challenges. A banking ai platform that treats vernacular as a configuration option rather than a core architecture requirement will fail at the quality and compliance thresholds that Indian collections demand.
Machine translation quality varies significantly by language pair. Tamil and Telugu are among the better-supported Indian languages in modern machine translation systems, with accuracy rates in the 93-95% range for standard financial communication. Bengali and Marathi are close behind. Assamese and Odia remain technically harder, with translation accuracy in the 80-85% range, sufficient for many use cases but requiring closer human review for compliance-sensitive collections messaging.
Tone is harder to translate than content. A collections message has to carry the right level of firmness without crossing into the coercive or threatening territory that the RBI’s guidelines prohibit. In English, you can control this precisely. In a machine-translated version of the same message, the nuances of register (formal versus informal, firm versus aggressive) often get flattened or distorted. A message that is carefully calibrated in English can arrive as unexpectedly blunt in Gujarati or unexpectedly passive in Malayalam if tone preservation is not built into the banking ai platform’s translation workflow.
Script handling adds complexity. Hindi, Marathi, and Sanskrit-derived languages use Devanagari script. Tamil, Telugu, Kannada, and Malayalam each use distinct scripts. Bengali and Odia have their own scripts. Punjabi uses Gurmukhi. Gujarati uses a distinct variant of Devanagari. A banking ai platform operating across all ten languages must handle character encoding, right-to-left display exceptions, and font rendering correctly across SMS, WhatsApp, IVR, and email, each of which has its own technical constraints.
Implementation Approaches: Choosing the Right Model
There are three practical approaches to vernacular collections, each with different quality-scale tradeoffs.
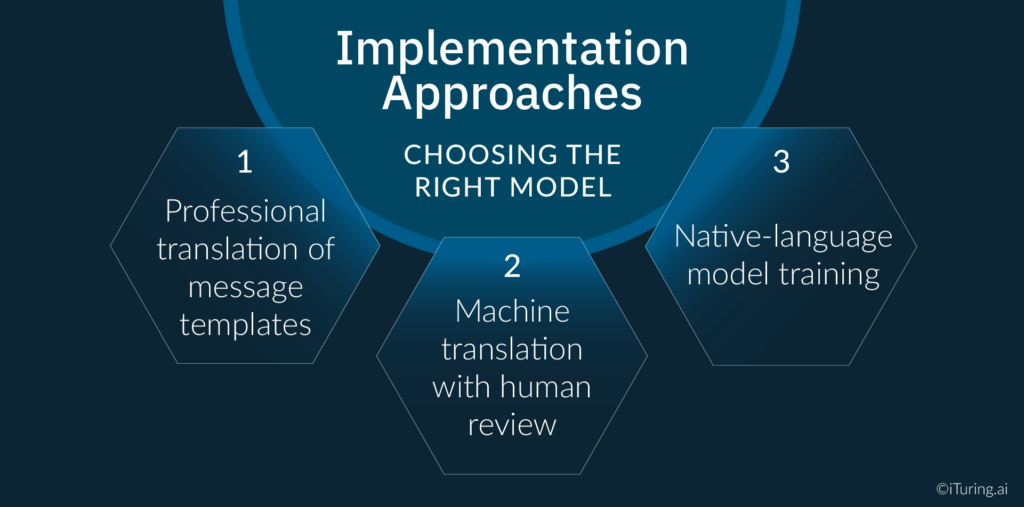
Approach 1: Professional translation of message templates. A human translator, ideally a native speaker with financial services knowledge, reviews and translates every message template before it goes live. The quality is high and culturally accurate. The constraint is scale: updating a library of templates across 10 languages when regulations change, products change, or DPD-stage messaging needs to be revised requires significant turnaround time and cost.
Approach 2: Machine translation with human review. AI-generated translation is reviewed by a native-language compliance reviewer before deployment. A propensity model layer can additionally prioritize which language-segment combinations warrant the most urgent human review, based on portfolio size, delinquency rates, and prior response data in that geography. New templates are generated quickly by the AI layer and validated by the human layer before going live. This is the approach most Indian banks and NBFCs with serious vernacular programmes currently use. It provides adequate quality across all ten major languages at a scale that professional translation alone cannot match.
Approach 3: Native-language model training. The AI system is trained from the ground up on native-language collections data, rather than translating from an English or Hindi source. This produces the highest quality output (messages that feel genuinely written in the target language rather than translated into it) but requires large volumes of language-specific training data and significantly greater development investment. This approach is emerging in pilots at large-scale lenders but is not yet standard practice.
For most Indian banks and NBFCs, Approach 2 is the current operational standard and the right place to start. The quality ceiling is high enough for full compliance and genuine borrower engagement. The scale is sufficient for a national portfolio.
Channel-Specific Vernacular Strategies
Vernacular implementation plays out differently across each channel in the collections workflow.
SMS. The constraint here is character count. Regional language scripts, particularly those using Unicode encoding, consume more characters per message than Latin script. A message that fits within a standard 160-character SMS in English may require 2-3 message segments in Tamil or Telugu, increasing cost and potentially reducing readability if the message breaks awkwardly across segments. Short, high-clarity messages in the regional script, focused on the payment amount, the due date, and a single call to action, outperform longer messages regardless of language.
WhatsApp. This is where vernacular collections delivers its highest channel-level impact. WhatsApp’s conversational format allows two-way communication, which means a borrower can respond in their own language and the system can handle that response intelligently. A propensity model processes those borrower responses in real time, routing payment plan queries to assisted channels, flagging hardship signals for human agent follow-up, and recording self-cure commitments without requiring any manual intervention. Churn prediction logic running alongside the propensity model identifies accounts where the response pattern suggests genuine disengagement versus intent to pay, enabling the right follow-up action before the account progresses deeper into delinquency. For over 530 million WhatsApp users in India, this genuine two-way vernacular interaction produces a materially different borrower experience than a one-way SMS or a scripted IVR flow.
IVR. Regional language IVR requires native-language voice recordings or high-quality text-to-speech synthesis in the target language. The quality of text-to-speech for Indian regional languages has improved substantially with recent AI voice synthesis developments, making automated IVR flows in Tamil, Telugu, Bengali, and Marathi far more natural-sounding than they were even two years ago. The key is clarity: IVR prompts must be simple enough to be understood by a borrower listening once, without the option to re-read.
AI voice calls. This is the most rapidly evolving capability in Indian vernacular collections. AI-driven outbound voice calls that conduct a collections conversation in the borrower’s regional language, detecting intent, offering options, and recording commitments, are moving from pilot stage to limited production deployment at several large NBFCs. Quality and naturalness remain variable by language, but the direction of travel is clear.
The Geographic Expansion Use Case
For banks and NBFCs whose growth strategy involves expanding credit portfolios beyond the Hindi belt and metro markets, vernacular collections is the operational prerequisite that makes the expansion commercially viable. Any ai for banks deployment supporting that expansion must include regional language capability as a launch requirement, not a retrofit plan.
India’s NBFC sector reached nearly Rs. 52 trillion in cumulative loans as of December 2024, with the sector projected to cross Rs. 60 trillion by FY26. The growth is being driven primarily by Tier 2 and Tier 3 geographies: NBFC credit lending by upper and middle layer NBFCs grew over 21% year-on-year as of September 2025, fuelled by MSME finance, consumer durables, gold loans, and personal finance in semi-urban markets.
Customer segmentation models that identify which borrower populations require which language treatment are the analytical foundation that makes geographic expansion operationally manageable. Without customer segmentation models assigning each account its correct language, channel, and DPD-appropriate message variant, a lender entering five new regional geographies simultaneously is running five disconnected collections campaigns with no systematic quality control. With customer segmentation models in place, the same operational infrastructure scales across all five geographies because every account is routed to the right treatment automatically.
Recovery rates in new geographies without vernacular capability consistently underperform by 25-30% compared to geographies where the lender communicates in the local language. The cost of retrofitting vernacular infrastructure after delinquency has accumulated in a new market far exceeds the investment in building it before expansion begins.
How iTuring Addresses This
iTuring’s banking ai platform supports 10 regional languages (Hindi, Tamil, Telugu, Bengali, Marathi, Gujarati, Kannada, Malayalam, Punjabi, and Odia) across SMS, WhatsApp, IVR, and AI voice call channels. Machine translation is validated against RBI compliance requirements before any message goes live in a new language, ensuring tone, frequency, and grievance disclosure standards are met in every language, not just English.
Customer segmentation models within the platform assign every account its correct language, channel, and message variant based on geographic location and observed engagement history, without manual configuration per borrower segment. The propensity model layer routes incoming borrower responses to the correct next action in real time, whether that is a payment plan offer, a hardship escalation, or a self-cure confirmation. Churn prediction runs in parallel, distinguishing language-driven non-response (which vernacular contact resolves) from genuine disengagement (which requires a different intervention strategy).
For ai for banks deployments supporting geographic expansion into Tier 2 and Tier 3 markets, the platform provides turnkey vernacular collections capability without requiring separate translation vendors, language-specific configuration projects, or additional compliance reviews. The 30% recovery rate improvement in non-Hindi, non-metro geographies reflects what consistent, culturally appropriate, RBI-compliant vernacular communication delivers in practice.
For collections heads planning a geographic expansion or currently managing underperforming recovery rates in regional markets,
Regulatory Disclaimer
The information in this blog is provided for general informational purposes only and does not constitute legal, compliance, or regulatory advice. Vernacular collections communications in India must comply with the RBI’s Fair Practices Code, Recovery Agent Guidelines, Digital Lending Guidelines, the Digital Personal Data Protection Act 2023, and all applicable state-level consumer protection regulations. Language data referenced in this post is sourced from India’s 2011 Census; actual language demographics may have evolved since. Recovery rate improvement figures are based on industry observations and iTuring client implementations; results may vary depending on geography, portfolio composition, channel mix, and borrower segment characteristics. Banks and NBFCs should consult qualified legal and compliance counsel before implementing vernacular collections programmes.
Sources: Yogeesh Shivanna LinkedIn: Building Financial Trust in Indian Languages | Reverie Inc: 2011 Census Indic Language Data Localisation | Wikipedia: Languages by Number of Native Speakers in India | Times of India: Smart Debt Collection and Recovery | RISQ ESG: India NBFC Sector December 2024 | EY: Private Credit in India H2 2025














